Web scraping con Python: montando la web con Flask
La quinta parte del #desafíoPython nos abre ya al mundo incorporando la visualización en web de toda la información que hemos conseguido capturar con el scraping.
¿Quieres disfrutar de todo el desafío con los problemas resueltos en vídeo?
Durante 9 horas de vídeo en castellano te cuento todos los detalles de como he creado esta aplicación. Apúntate al curso del Desafío Python
Este es el quinto artículo de la serie del #desafíoPython. Consulta la primera, segunda, tercera y cuarta parte. También la sexta.
¿Qué hemos conseguido hasta ahora? ¶
Llegamos aquí al hito 5 de la planificación que hicimos de forma previa.
Hito 5. Mostrar la información almacenada de forma sencilla
Alcanzamos ya la versión 0.4.1. El código puedes encontrarlo en GitHub.
¿Qué dificultades nos hemos encontrado? ¶
No ha sido un hito con grandes dificultades, pero sí se ha aumentado el valor de lo que ejecuta el código en mayor medida que en las entregas anteriores.
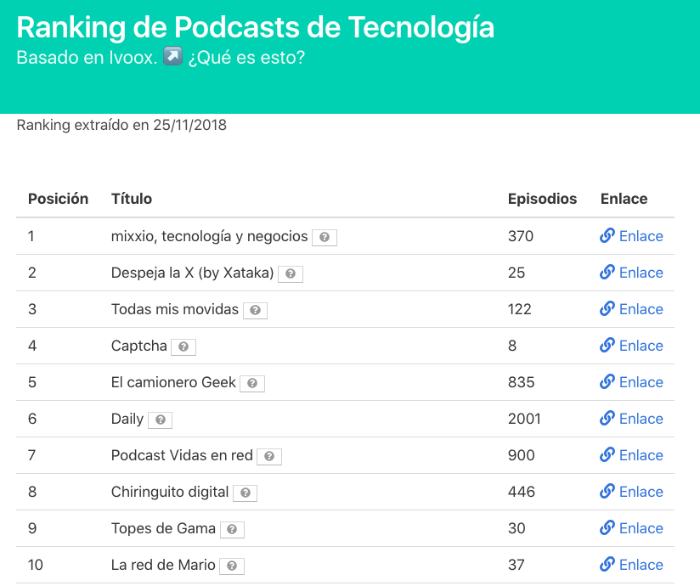
Histórico de datos ¶
He aprovechado para realizar algunas mejoras concretas. La más importante ha sido considerar nuestro “storage” de datos del ranking como una herramienta histórica.
Aunque solo son los primeros pasos ahora cada vez que ejecutemos el “build” del ranking tendremos un fichero de datos con la marca fecha en formato “YYYY-MM-DD”. Quizás así podríamos montar una herramienta de más valor recuperando datos en un línea temporal.
También se incluye la pequeña dificultad de agregar una expresión regular para la lectura de la fecha del fichero más reciente. Aparece toda la lógica en nuestra clase “Storage” que es la que se encarga de guardar y cargar los ficheros. De forma sencilla se utilizan las librerías “re”, “os” y “glob” para conseguir el resultado.
Por fin llega la web ¶
Una de las excusas para comenzar este #desafíoPython era comprobar la facilidad con la que una lógica “encerrada” en una ejecución por línea de comandos podía ver la luz a través de una interfaz como la web era “coser y cantar”.
Al contrario que en otras tecnologías como en PHP donde todo se construye ya para la web, Python es más multidisciplinar y el proceso de publicación de los resultados en la web ha sido muy sencillo.
Usamos Flask y, en combinación con la lectura de datos que hemos mejorado, cargamos la información justa.
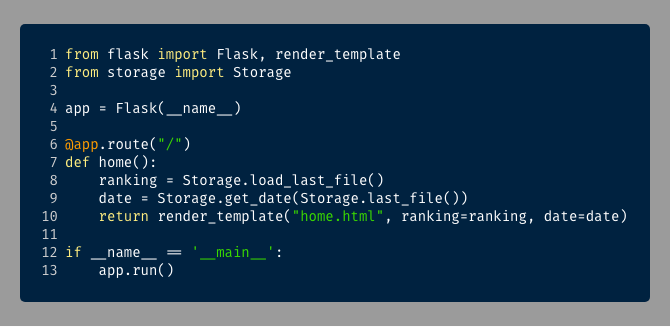
Es la vez que con menos esfuerzo he conseguido montar un artefacto web disponible para que, en el hito final, podamos publicarlo en la web.
Bulma, nuestro aliado fiel ¶
Flask utiliza el motor de plantillas Jinja, que utiliza muchos conceptos vistos en sistemas similares como handlebars o twig.
Así que de momento con una sola template colocada en la carpeta oportuna podemos generar toda nuestra capa de presentación. Utilizamos la librería Bulma para preocuparnos solo por nuestros datos y la lógica de presentación. Partimos de la plantilla básica y lo demás ha sido ir añadiendo los elementos necesarios.
Además añadimos la extensión Bulma tooltip para añadir junto al nombre de cada podcast la descripción en forma de “tooltip” para que se muestre solo cuando pulsemos sobre el icono de interrogante. No tenía muy claro si seguir almacenando la información de la descripción, así que hemos adaptado la última parte del circuito (la capa visual) para darle sentido a ese dato.
Puedes ver los detalles de este desafío con todos los problemas resueltos y la aplicación real funcionando en el curso en vídeo (9 horas)
¿Cuando completaremos el hito 6 del proyecto? ¶
Es sencillo, cuando tengamos colgada la aplicación en internet y cualquiera pueda consultarla.
Sería un plus si la propia aplicación es capaz de ‘autogestionarse’ para que nosotros no tengamos que intervenir. Por ejemplo, que la subida de nuevas versiones esté automatizada. También sería ideal si podemos conseguir que capture el ranking de podcasts una vez a la semana, para que siempre se ofrezca la información actualizada.
Recursos para lograrlo ¶
Los recursos se siguen acumulando. En esta ocasión, como estamos casi al final el principal es el de cómo conseguir publicar nuestra aplicación en internet para hacerla funcionar.
¿Qué tal te ha ido? ¶
A Franco Cedillo (@paracuerdas en twitter) le ha ido genial.
Ha utilizado la excusa del scraping para montar toda una evolución hacia una herramienta de análisis de datos que comparte con nosotros en formato de Jupyter notebook y varios repositorios de GitHub como este sobre el scraping de episodios. ¡Felicidades por todo tu trabajo!
Cuéntanos como te va con esta aventura. Utiliza los comentarios o en twitter con el hastag #desafioPython.
Escrito por:

Daniel Primo
12 recursos para developers cada domingo en tu bandeja de entrada
Además de una skill práctica bien explicada, trucos para mejorar tu futuro profesional y una pizquita de humor útil para el resto de la semana. Gratis.