Web scraping con Python: proyecto publicado y conclusiones finales
La última parte del #desafíoPython finaliza la saga publicando el proyecto en la web y convirtiendo nuestro aprendizaje en un proyecto real.
¿Quieres disfrutar de todo el desafío con los problemas resueltos en vídeo?
Durante 9 horas de vídeo en castellano te cuento todos los detalles de como he creado esta aplicación. Apúntate al curso del Desafío Python
Este es el sexto y último artículo de la serie del #desafíoPython. Consulta la primera, segunda, tercera, cuarta y quinta parte.
¿Qué hemos conseguido hasta ahora? ¶
Este es el 6 de la planificación inicial que preparamos para la ejecución del proyecto.
Hito 6. Publicarlo en internet.
Alcanzamos ya la versión 0.5. El código puedes encontrarlo en GitHub.
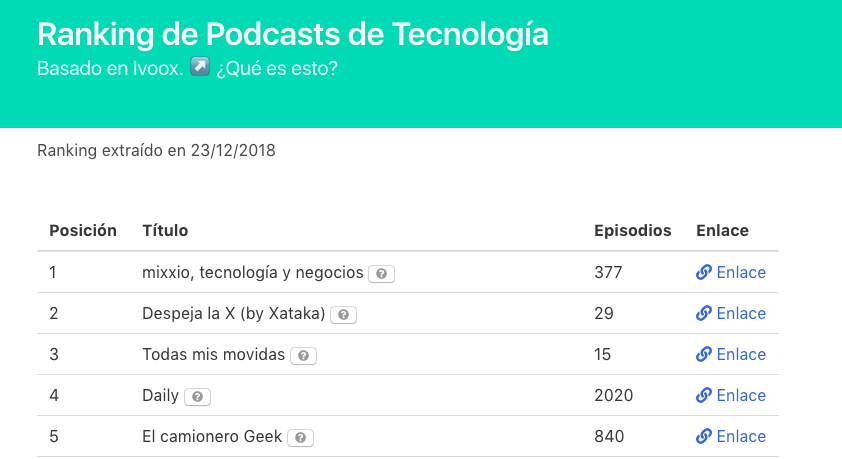
Puedes ver el proyecto finalizado en podcast-ranking.herokuapp.com.
Hemos conseguido mantener los hitos marcados inicialmente, ajustando la tarea a la definición inicial, lo cual considero un buen logro (ver más abajo las conclusiones finales ;)
¿Qué dificultades nos hemos encontrado? ¶
Más de las esperadas, dado que un de las consignas no escritas el proyecto era poder desplegarlo en algún servicio gratuito. Esto ha hecho que una parte fundamental de la lógica, la generación del ranking de forma automática, sea ahora prescindible.
Despliegue en la nube ¶
Tres eran los entornos posibles para publicar la aplicación, cada uno ha tenido sus pros y contras, aunque en todos se ha utilizado la versión gratuita.
Openshift Online
De la mano de RedHat ofrecen un aprovisionamiento de servicios en a nube gratuito. Tras varios días esperando sigo esperando que lo concedieran. Al parecer tienen una sobrecarga de peticiones de su plan “Starter” y no he podido acceder a él.
PythonAnywhere
Aloja, ejecuta y programa Python en la nube con PythonAnywhere. Así es y tiene muy buena pinta. Es un cloud diseñado específicamente para Python y es muy saludable dado que te ofrece todo el soporte para ejecutar comandos, acceder a consola, crear servicios de web…
La única pega es que en su servicio gratuito el acceso a recursos externos está “capado” y, por tanto, no está permitido el scraping de dominios que no tienen API activa. Así que nos deja fuera de juego porque ivoox no cumple esto.
Heroku
La popular plataforma para desplegar aplicaciones en la nube, heroku fue mi primera opción. Tiene algunas particularidades en su instalación, pero todo se hace más llevadero con sus wizards.
Esto se refuerza con el hecho de que después de configurar el proyecto a través de la línea de comandos, cada vez que haces un git push heroku master estás desplegando todo el proyecto.
Tiene soporte para Python y es visualmente muy cómodo de utilizar. Por desgracia con los dyno gratuitos no parece que sea fácil conseguir ni persistencia de datos ni ejecución de tareas programadas.
Generación del ranking en la primera ejecución ¶
Finalmente la aplicación se despliega en heroku. Pero al no poder ejecutar esas tareas programadas y regenerarse la instancia cada vez que pasa un determinado tiempo sin ejecutarse, tenemos que cubrir la falta de datos generando el ranking en formato Json cada vez que cargamos la página. Solo si no existe, claro.
Esto pone contra las cuerdas a la aplicación, ya que perdemos parte del potencial de poder lanzar ese scraping desde el servidor y hacer que la carga de la web solo sea una consulta.
Por eso verás en el repositorio que se añaden dependencias de la librería “apscheduler” para crear tareas programadas en heroku. No me resisto a eliminarlo, porque creo que es el camino a seguir en un alojamiento de pago.
¿Qué podemos hacer para mejorarlo? ¶
Infinidad de cosas, comento algunas, aunque bienvenidas son todas las sugerencias:
- Guardar el histórico del ranking en una base de datos. Es algo que pide ya desde el inicio el sistema y que sería una fortaleza de esta aplicación. No descarto ejecutarlo en un hito extra en las próximas semanas. Para esto habría que pasar a un hosting de pago.
- A raíz de lo anterior surgen muchas cosas más: crear gráficos temporales con la posición de cada podcast, consultar cuando entró en el ranking, exportar la información en formato CSV, subidas y bajadas en el ranking…
- Almacenar otras categorías del ranking de ivoox, no solo la de “internet y tecnología”. Hacer la navegación por esas categorías.
- Recuperar más datos de cada podcast, como por ejemplo los episodios más escuchados, favoritos o comentados y el último episodio listo para reproducir desde el ranking.
- Con mineria de datos extraer comportamientos interesantes: que podcast son los que tienen una mejor proyección, nuevas apariciones en el ranking, cual es la media de escuchas por podcast y episodio…
Percepciones finales ¶
Puedes ver los detalles de este desafío con todos los problemas resueltos y la aplicación real funcionando en el curso en vídeo (9 horas)
Muy positivas. Enfrentarse a un nuevo reto y contarlo ha sido una experiencia que voy a repetir en breve. Saber que personas que leen esto se van a animar a crear su propio proyecto, es algo que ilusiona, pero también hace sentir sobre mi la responsabilidad de contarlo TODO de la mejor forma posible.
Lo más positivo del #desafíoPython ha sido:
- Programar con Python es un placer.
- Los hitos se han cumplido sin necesidad de modificarse.
- El scraping es más sencillo de lo que parece y aporta un nuevo valor a datos que parecen poco estructurados.
- El git semántico (del que hablamos en el episodio 66https:///www.danielprimo.io/podcast/66)) es algo que voy a incluir en mis próximos proyectos.
- Esforzarse en tener un código más legible y formular un aprendizaje ha sido para mi lo más provechoso.
En la parte negativa:
- El despliegue en la nube ha condicionado el broche final del proyecto y ha hecho que se prolongara en el tiempo.
- Se podría haber conseguido el mismo resultado en menos tiempo (o menos hitos).
- El equilibrio entre la sencillez y la ambición se ha decantado por lo primero. Este proyecto pide una ampliación a gritos :)
Ha sido para mi un placer compartir todo esto contigo. Pregúntame todo lo que quieras si tienes dudas sobre como acometer este desafío.
Y ahora, ¿qué se te ocurre? ¶
¿Qué ideas se te ocurren para ampliar el proyecto? Puedes usar los comentarios de este blog o en twitter con el hastag #desafioPython.
Escrito por:

Daniel Primo
12 recursos para developers cada domingo en tu bandeja de entrada
Además de una skill práctica bien explicada, trucos para mejorar tu futuro profesional y una pizquita de humor útil para el resto de la semana. Gratis.